2018 has gotten off to a great start for me. Good things have happened on all fronts, and one of them is that I finally have a prescence on Spotify! I released this EP on Soundcloud back in 2014, as a limited attempt to get my work out there, but now it’s available for the masses!
Burning Chrome is an attempt to capture the cyberpunk aesthetic by combining a dark, distorted electronic sound with electric guitars and 80’s synth sounds. It’s quite a leap from my usual work, and I’m very happy with the end result.
After working for a while on my news crawler, I’ve stopped dead in my tracks. I’m fed up with various news agencies, and have started to question the value of following any news at all.
For starters, there are several news sources that are the journalistic equivalent of junk food – their articles are often just a couple of sentences, and more than half the content is coverage of celebrities.
I’ve also learned that most news agencies buy their stories (or at least a large share of them), and therefore for international news (which is what I prefer to read) I would find greater value in just following Reuters directly than following any newspapers from my country. The news agencies with real journalists and long-form articles seem few and far between.
One of my goals was to cut through the noise and make it easier to find the “important” stories – instead I ended up creating a flood of low-value information. While the content is indexed well enough to enable one to find similar articles, that need for “deeper journalism” hasn’t occurred in my daily news consumption since I started the project.
The tool I’ve been building could probably be useful for a journalist, but it’s not really worth the effort of using myself. This realization was a real blow, as not using your own product is a terrible signal to send.
In short, I’ve put this project on hold. I might pick it back up in the future, but right now it’s become actively unappealing to me.
My relationship to mass media has changed, possibly as a consequence of this project – I no longer manically cycle through the different news websites, but rather drop by the “real” sources (e.g. Reuters, who is the source of all international news in Norway, and Al Jazeera, who still produces long-form quality content) a couple of times a week. My faith in newspapers has been thoroughly shaken, but maybe this was the wake-up call I needed.
I’ve previously written about the first iteration of my news crawler. The novel idea I built everything upon, that triads of keywords would bubble to the top, appeared faulty and did not bring a natural bubbling of trending stories as I first imagined it would.
Some time passed before I started building my second iteration. I had to bide my time, note down and reflect over further ideas, as well as do more research. One major discovery that would greatly affect the second iteration was the Python library Newspaper. It drastically simplifies the spidering and crawling for me, although one con is that it gives tons of duplicates (as it fetches stories from all subdomains / different newsfeeds a news agency has) – fortunately this can be dealt with in the code.
Newspaper has two more advantages I could utilize – it extracts a set of keywords from the article (which means I can use more than just the title), and does some clever NLP to summarize the article (with differing results, unfortunately some stories end up as a jumbled mess).
My first iteration did everything from scratch and used PHP, but in the second iteration I moved on to Python for the input side (although the front-end of the application is still pure PHP). I ended up with far fewer lines of code and yet more functionality – this really felt like finding the holy grail!
My new solution is a greatly enhanced version of the first one. Where I started out with simply a HN-like list of headlines and sources with keywords extracted from the headline, the system now works with an enhanced set of keywords from the entire article. I can browse by keywords (or combinations thereof), and I can see the trending keywords for the past couple of hours, days or weeks. I also have an article view (I had that before, but with only the cleaned text of the article) with an introductory blurb based on the NLP function of Newspaper.
An article seen in the Newsroom app
Unfortunately, after running my new version for a little while I realized it still wasn’t at the level I wanted it to be. For one, the NLP summaries of articles were unreliable and at times nonsensical. That reduces its value drastically, and I suppose using the simple blurbs given in RSS feeds could probably be a better choice. I’ll be giving that a shot in the third version.
Now for the keywords – simply extracting keywords from the article does not seem good enough for my purposes. It turns out that the “trending keywords” at any given time is dominated by various versions of “Trump”. I need to handle aliases, but also somehow identify some descriptive information about the keyword. I’m not sure if I can manage to identify the subject and object of sentences or headlines (given that the keywords are already extracted by the time I get to them, but also the fact that I wouldn’t know where to start with such a task), but something I could do is to handle it manually and build the dataset over time. For instance I could set up classifications such as verb / adjective / subject, where I lump subjects and objects together since I can’t really get the context.
My application has advanced quite a bit since its inception, but I still keep finding things to improve. As I start working on the third iteration, I’m hoping it will turn out to be ready for real use.
Today I’m going to share the story of how I helped make my organisation more data driven in their decision making.
Initial situation
I joined the company, an NGO focused on child sponsorship, in 2014. For the past couple of years they’d had trouble finding people competent in SQL and data management, and there was a huge backlog of reports and extracts waiting to be done. We had a decent amount of information available in our CMS (customer management system) – the business had been running since 1997, which means there was 20 years of data available (of variable quality, but enough to extrapolate some patterns). The historic data had been used occasionally for analyses by external companies, but we didn’t use it for anything internally. Old data was mostly left to rot.
Starting up – external analysis
When I was recruited into the job it was primarily to support the CRM team as a technical resource and system owner. There was also a demand for someone who could understand the data structures behind our systems, and could extract the required data for external consultancies who would help us do analyses and find patterns in customer behavior.
The goal of the initial project was to identify customers who are likely to quit, or churn (as is the CRM term). The team had already decided on a bunch of metrics they thought could affect this, such as e.g. the number of unpaid invoices and how long it had been since we got in touch with them. Identifying and extracting all this information was my task, and it was an ideal way to get to know the data structures I had to deal with (our application’s database was not exactly ACID compliant, and had a steep learning curve).
I built a staging database to contain all the calculated values, and stored it all in one huge, flat table that was populated one column at the time. When it was time for our consultants to do their data crunching, we could simply send them an extract of the complete table. Any tweaks or new fields that came up as requirements along the way could be done quickly and implemented with a quick rebuild.
We finally got our results and ended this project, leaving the staging database dead for now. We got the rules we needed to predict who was 50% more likely to churn and added the relevant measures in our customer handling procedures. This was certainly a step in the right direction.
Building on what I learned
After completing the analysis project we started exploring the idea of a permanent staging database, or a data warehouse. This could surely make a ton of information much more accessible to the organisation, and could take us in a more data-driven direction. In addition, we could move our CRM tool to use the staging database as a data source rather than the live system, simplifying the logic we needed in the tool and most importantly reducing the load on a live system (we had cases where employees were unable to update data in the system because of blockage from heavy queries in the CRM tool).
The development of this system was done in a very small team – a colleague and myself, with the occasional insight from a consultant. We built on the previously developed definitions and queries, and expanded thoroughly with every useful dimension we could come up with. The problem with such a large dataset is that it takes a rather long time to build, which means that the data will never be fully up to date. To mitigate this issue somewhat, we put together a daemon that watched the source database for updates and then pushed these to an update queue in the warehouse. While not real-time, this would ensure that data would at least update throughout the day. We also set up a full rebuild at midnight, which would purge the queue and start fresh. This would ensure that if the queue got backed up, it would only be a problem that one day.
The system would also have to support multiple data sources – while the system did have a concrete set of base tables, it would also have a structure for additional data. For instance, we would fetch usage data from our web portal as well as supporting a geolocation-based customer segmentation system we were planning to try out.
Once we had the data warehouse established and running, I started looking into what we could do to utilize the data. Thinking back to our churn analysis where the consultancy had automated their analysis with an ancient excel worksheet (which took days to execute), I was certain that modern technology could outperform them while simplifying the process drastically. I’d seen R discussed time and time again on Hacker News and StackOverflow, so I figured that would be a logical place to start.
Figuring out the basics of R was simple enough – it was very forgiving for a scripting language, and it helped me visualize data in myriad ways that made it possible to point out problematic areas. Using the data warehouse as input data made it so much easier, as the data was already cleaned and prepared when I fetched it (apparently this part, the data engineering, is what takes up to 80% of the time when working with data science). After a while I was confident enough to build a full script that took a dynamically sized dataset, ran a basic linear regression test between every combination of columns, then returned the significant values. This actually gave me a wealth of insight into our data such as the relationship between age and payment frequency. Unfortunately, communicating these findings to the key decision makers proved difficult, but at least we were getting somewhere!
Democratization of data
At this point in time, the data warehouse was giving us decent value for money, but it was all still gated with me as the gatekeeper – There was not much interest in the data yet, and to find anything one would still need to put together queries (which I was the only one capable of doing). Any sign of complexity seemed to turn the users off of the data.
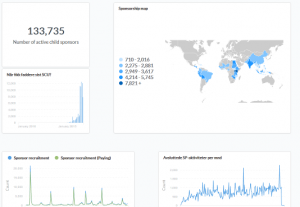
Recently I discovered a tool called Metabase through a discussion on Hacker News. An open source data visualization/exploration tool was just the thing to tickle my interest, so I set it up on an internal server to see how it worked. I used the data warehouse as a data source, and found that it was not only very feature-rich, but also user friendly enough that non-technical people might be able to use it. I once used this tool to answer a question during a meeting, and it appears those present immediately saw the value of both the tool and the data!
A Metabase dashboard
This was the pivotal step in the process – Now a whole team is on board with using the data warehouse, and have started building dashboards to watch the most important metrics. They’ve even found new useful metrics that can help understand our sponsors better! In other words, ease of use was a crucial element in attracting the users’ attention. Getting them interested and invested in the data is as important as building the entire technical stack in the first place.
Later on, if given the green light, I may share technical details and some of our findings here.
News websites have always been horrible, but lately it feels like they’re somehow getting even worse. What do I mean? Well, for one, the pages are bloated. Megabytes of javascript and images are loaded just to read a couple of paragraphs of text. The front pages are usually very loud and cluttered, and the headlines are often clickbaity rather than explanatory. Finally, the stories don’t usually give any context to the issue they discuss, but rather simply assume you’ve read their other articles earlier (especially when there are big stories in the news, the information is often spread into myriad different stories that don’t have any apparent chronology).
I wanted to get around these issues, so I started drafting a system to organize and present the information the way I wanted it.
I started out with a couple of initial premises:
I wanted to be able to read the news based on the stories and how they develop rather than reading a single isolated article. This meant I had to find a way to identify what articles/headlines are discussing the same story.
The pages must be minimalistic – no (or few) pictures, fast loading, as little javascript as possible.
Multidimensional: I want to be able to explore the news through multiple dimensions. This includes source (site), category (e.g. financial news, sports) and keywords.
Sentiment scoring: I’d come across software that could perform sentiment analysis on a text, then return a score. I had ambitions to integrate this to give a view of e.g. the sentiment development over time per keyword and/or source. Unfortunately I did not find the time to do this part during the first iteration.
I had a simple idea I started out with – Any developing story ought to be identifiable through a combination of three of the keywords (a triad) in the headline, and the context (earlier stories) would share one or two keywords. In other words, a story would probably show up in multiple papers with different titles, but with at least three similar elements. I figured the most popular combinations would most likely bubble up to the top naturally, giving me a solid list of which (combinations of) headline keywords were trending.
Here’s an outline of how I built my system:
I started out by building a web crawler. To keep it simple I stuck to using RSS feeds as the data source, then put together a side system to fetch and parse the articles themselves. I put great care into the data structure, as it would grow very fast once I started running the crawler regularly. I came up with a novel idea for the keyword triads; I made a table with three columns to store these. I would sort the keywords alphabetically, then build every possible combination of keyword in a sorted manner – that way I would avoid duplicate combinations in different order.
Now I needed a front-end – not as exciting to describe, I simply put together a table-like structure which would show headlines and source, with a spot for the sentiment value and a link to the article on its website.
After setting the system up and running some early tests, I realized that my initial assumption was wrong. I was unable to group the same story from different sources because the headlines differed more than expected. I got clickbait like “will make you” dominating the top of the list, which obviously do not identify one and the same story. After filtering out the news sources teeming with clickbait, I found that most “real” news are covered different enough between agencies that the headlines can be completely different. Every combination of words from one common story dominated the results at one time (when agencies actually did post the same headline), and all in all there was more garbage than value. This put an abrupt stop to this iteration of the project, and sent me back to the drawing board.
This was still a learning experience, and gave me the necessary insight to start building the second iteration.
Turns out there’s a trend where the shittiest titles tend to be the most prominent – If I’d read this article before starting, I would probably never have finished the first iteration: Study of most commonly shared headlines
There’s a thought that’s occupied my mind lately – working in software, will I ever leave a lasting legacy? A central concept in the software world is building solutions that will inspire new and better solutions, and so the history of the earlier pieces is often lost.
I grew up being taught that anything you put online stays online. This was meant as a privacy safeguard more than anything else, but by the same reasoning I thought that my projects would also stand the test of time. Even if people forgot, the data would be there.
My first software project was an encyclopedia and skill calculator for an online game called Tibia. This was long before wikis were a thing, mind you. The game was still rather basic back then, and users often built tools one could use on the side to compensate for missing features. My inspiration to do this was a user called Loki X, who built a couple of tools to supplement the game. The only one I remember now is the friend list, which fetched a list of the players who are online from the game servers and displayed which of your friends were online. The tool became an integral part of playing the game, and I wanted to make a similar impact.
Today, when I query google for “Loki X” or “Loki tools”, nothing shows up in the results. My trigger for getting into software development has practically been purged from history. When it comes to the tool I made, it has suffered a similar fate. The web server I hosted it from is long gone, and the community site that also hosted it has disappeared as well. Luckily, it seems to live on in some people’s memories. Recently a thread discussing the game showed up on /v/, and I asked if anyone remembered Tomes of Knowledge. To my surprise, someone replied with a picture of their desktop, with my shitty old icon still sitting there!
Both Loki’s tools and my own application served as building blocks in one way or other, but as the game itself declined they became irrelevant. The only legacy I was left with was a simple piece of trivia that can’t even be verified anymore (as the web servers shut down, and I didn’t keep any offsite backups of the code).
This story is from when I was a teenager, long before I became a professional software developer. I’ve worked on a multitude of personal projects since, but none that have had the same reach as this one simple application made by a bored teenager. And even this application disappeared from history.
This post may sound more negative than I intended. It’s not all doom and gloom, as these thoughts have spurred me into finally setting up a proper github account and beginning to share my smaller projects with the world. I’ve kept thinking everything I make on my free time is insignificant, but if it can serve to inspire a better product (or even be integrated into something) then I can finally say I’ve done my part to serve human progress. And that would be something, wouldn’t it?
Disclaimer: This is a solution done in T-SQL aka Microsoft SQL. It may be possible to recreate in other database systems, but I haven’t explored that option yet.
This is a solution to a very specific problem I’ve encountered, which might prove useful to others. A while ago I started looking into the code of our solution for overdue payments (in regards to subcriptions, e.g. the customers are billed monthly but not always paying), which appeared to have some issues. I found an oddly constructed procedure where I couldn’t for the life of me understand why it would’ve been built that way. My first instinct was to try to build it from scratch and see what the major showstopper would be.
The biggest hurdle was identifying each specific cluster of undisrupted payments, as that’s not quite straightforward when looking at the data.
To take you through this process, let’s start off by defining the table we’re working with. I’ll exclude fields that aren’t relevant, keeping this explanation as simple as possible.
SubscriptionID (bigint – Identifier for the subscription whose payment is overdue)AmountDue (float/money)
AmountPaid (float/money)
DueDate (date)
This should be enough to get us going.
Now, on to the previously mentioned hurdle; How do we split the data into groups for each series of completed (or missing) payments?
Our first query gives a list of all the missing payments. This is where we start.
SELECT
i.SubscriptionID,
i.DueDate
FROM Invoices i
WHERE i.AmountPaid = 0 /* let's only look at the completely unpaid ones for now */
AND i.DueDate < GETDATE()
Now comes the clever part – a trick I came across somewhere on Stack Overflow. We want to group each series of recurring payments into its own group, and figure out how long the break lasted and how much was due. There isn’t any obvious variable to group this data by, but we can create one! We know the time series will be increasing by 1 month for each row, and so any deviation from that formula should mean a break in the pattern (and thus a new series).
You may be familiar with the MSSQL function ROW_NUMBER(), which can enumerate rows based on your given criteria. This will give a steadily rising number for the rows we’re already looking at. It won’t care whether there was a break in the dates or not, so we need something more. By calculating the number of months (for a monthly recurring payment – if the intervals are different then this method would need to be adjusted for that) that have passed since a given point in time, we’ll be closing in on our goal.
ROW_NUMBER() OVER( ORDER BY i.SubscriptionID, i.DueDate ) AS rn,
DATEDIFF(month, '1900-01-01' , i.DueDate) AS mnth
These two combined will give us what we need. The number of months minus row number will give the same result for each recurring record, giving us a variable we can start grouping them by!
SELECT
ROW_NUMBER() OVER( PARTITION BY SubscriptionID, Batch ORDER BY DueDate) AS IntervalsMissed,
DueDate, SubscriptionID,
ROW_NUMBER() OVER (PARTITION BY SubscriptionID ORDER BY InvoiceStartDate DESC) AS rn -- the row with rn=1 would be the most recent
FROM (
SELECT
i.SubscriptionID,
i.DueDate,
DATEDIFF(month, '1900-01-01' , i.DueDate)- ROW_NUMBER() OVER( ORDER BY i.SubscriptionID, i.DueDate ) AS Batch
FROM Invoices i
WHERE i.AmountPaid = 0
AND i.DueDate < GETDATE()
) a
Here we go, the resulting data set gives us a list of every cluster of missed payments our customers have, complete with how many recurring months they missed their payments for each of them. In our case we use this to identify those who are currently in a miss-streak, and ignore the historical data. There’s quite the number of things one can do with such data, but that’s a topic for another day.
Hello, curious reader.
It’s been 5 years since I last kept a blog. My exit coincides with the beginning of my professional career, which I can assume was either due to too much free time during my studies or simply the realization that I actually had more to learn than to teach.
Now, some time later, I feel I’ve done a couple of things that may actually be worth sharing, so I’ll try to get this thing started again.
This blog will first and foremost reflect my professional life, covering everything from server maintenance and shell scripting to software development and interesting database solutions.
I currently work for a NGO where I work with the database and our core applications (and do some minor coding on the side whenever I see a way to improve workflows). I’ve also been part of a two-man team that built and deployed a data warehouse solution in several of our European country offices.
Why “Anticode”?
The name stems from one of my music projects, which I considered a vacation of sorts from my day job. The name stuck, and is markedly more unique than my real name (a quick google search of my name is unlikely to give any results pointing to me).
So there we go. Time to get this thing up and running.