Tying into my previous post (regarding the data warehouse and aggregated tables), here’s a more technical description of how I put together a script for simple correlation discovery in R.
Bear in mind – this is using basic Pearson Correlation and is not at all on par with “proper” data exploration methods such as gradient boosting and the likes. I’m using the methods cor.test() and cor(), and I catch the “significant” data which has p-value below 0.05.
This test can only work with integers – this means that I can’t use textual fields from the database directly. A way to handle that is to categorize the significant values as binary choices, e.g. if you’ve got the customer categories “individual”, “company” and “school” then you’d set up case-based values named is_individual, is_company and is_school.
The query would go something like this:
SELECT
CASE WHEN category LIKE 'individual' THEN 1 ELSE 0 END AS is_individual,
CASE WHEN category LIKE 'company' THEN 1 ELSE 0 END AS is_company
FROM sometable
With this data in hand, we’re ready to run an analysis. I’ve built this script to find correlations in datasets of any size, but I’ll just include a couple of rows in the sample script (my real queries tend to be up to 100 lines, and do not add anything to this example). Instead of describing textually how I’ve built the script, I’ve added comments throughout the code to better explain what I’m doing where I’m doing it.
Unfortunately, it seems I’m unable to recreate my indentation in this post, but it only makes the loop a bit less readable. Bear with me.
library(RODBC)
dbhandle = odbcDriverConnect('driver={SQL Server};server=mydatabaseserver;database=warehouse01;trusted_connection=true') # trusted_connection does authentication through your logged-in AD credentials
query = "
SELECT
MonthlyAmount,
DATEDIFF(day, FirstInstalmentPaymentDate, GETDATE()) AS DaysSinceFirstPayment,
NoOfMissedInstalmentsPast2Years,
NoOfAdHocPaymentsPast2Years,
Age,
DATEDIFF(day, LastContacted, GETDATE()) AS DaysSinceLastContact,
FROM warehouse01.dbo.customer;"
res = sqlQuery(dbhandle, query)
# these two arrays/vectors are used to match column names to values inside the loop
columnnames = colnames(res)
columns = seq_along(res)
results = vector()
# iterate through all columns
for(i in columns){
# iterate through the columns after the active one,
# to avoid duplicate matches
inner_columns = columns[i:length(columns)]
# only handle outer row if it is numeric
if(is.numeric(res[[i]])){
# same numeric check for the inner ones
for(j in inner_columns){
if(is.numeric(res[[j]])){
# correlation testing
tmp = cor.test(res[[i]], res[[j]], na.rm = TRUE)$p.value
coef = cor(res[[i]], res[[j]], use="complete")
# if significant find, add to a results-array
if( (tmp < 0.05) && (tmp > 0) ){
results = c(results, columnnames[i], columnnames[j], coef)
}
}
}
}
}
# make the results-vector a matrix for readability
results = matrix(results, ncol = 3, byrow=T)
odbcClose(dbhandle)
This script leaves me with a table (or matrix, as it’s called in R-land) consisting of three columns: The first two are the pair of columns tested and the last is the correlation coefficient (strength). RStudio allows for sorting and filtering, which makes it easy to find the strongest correlations.
Today I’m going to share the story of how I helped make my organisation more data driven in their decision making.
Initial situation
I joined the company, an NGO focused on child sponsorship, in 2014. For the past couple of years they’d had trouble finding people competent in SQL and data management, and there was a huge backlog of reports and extracts waiting to be done. We had a decent amount of information available in our CMS (customer management system) – the business had been running since 1997, which means there was 20 years of data available (of variable quality, but enough to extrapolate some patterns). The historic data had been used occasionally for analyses by external companies, but we didn’t use it for anything internally. Old data was mostly left to rot.
Starting up – external analysis
When I was recruited into the job it was primarily to support the CRM team as a technical resource and system owner. There was also a demand for someone who could understand the data structures behind our systems, and could extract the required data for external consultancies who would help us do analyses and find patterns in customer behavior.
The goal of the initial project was to identify customers who are likely to quit, or churn (as is the CRM term). The team had already decided on a bunch of metrics they thought could affect this, such as e.g. the number of unpaid invoices and how long it had been since we got in touch with them. Identifying and extracting all this information was my task, and it was an ideal way to get to know the data structures I had to deal with (our application’s database was not exactly ACID compliant, and had a steep learning curve).
I built a staging database to contain all the calculated values, and stored it all in one huge, flat table that was populated one column at the time. When it was time for our consultants to do their data crunching, we could simply send them an extract of the complete table. Any tweaks or new fields that came up as requirements along the way could be done quickly and implemented with a quick rebuild.
We finally got our results and ended this project, leaving the staging database dead for now. We got the rules we needed to predict who was 50% more likely to churn and added the relevant measures in our customer handling procedures. This was certainly a step in the right direction.
Building on what I learned
After completing the analysis project we started exploring the idea of a permanent staging database, or a data warehouse. This could surely make a ton of information much more accessible to the organisation, and could take us in a more data-driven direction. In addition, we could move our CRM tool to use the staging database as a data source rather than the live system, simplifying the logic we needed in the tool and most importantly reducing the load on a live system (we had cases where employees were unable to update data in the system because of blockage from heavy queries in the CRM tool).
The development of this system was done in a very small team – a colleague and myself, with the occasional insight from a consultant. We built on the previously developed definitions and queries, and expanded thoroughly with every useful dimension we could come up with. The problem with such a large dataset is that it takes a rather long time to build, which means that the data will never be fully up to date. To mitigate this issue somewhat, we put together a daemon that watched the source database for updates and then pushed these to an update queue in the warehouse. While not real-time, this would ensure that data would at least update throughout the day. We also set up a full rebuild at midnight, which would purge the queue and start fresh. This would ensure that if the queue got backed up, it would only be a problem that one day.
The system would also have to support multiple data sources – while the system did have a concrete set of base tables, it would also have a structure for additional data. For instance, we would fetch usage data from our web portal as well as supporting a geolocation-based customer segmentation system we were planning to try out.
Once we had the data warehouse established and running, I started looking into what we could do to utilize the data. Thinking back to our churn analysis where the consultancy had automated their analysis with an ancient excel worksheet (which took days to execute), I was certain that modern technology could outperform them while simplifying the process drastically. I’d seen R discussed time and time again on Hacker News and StackOverflow, so I figured that would be a logical place to start.
Figuring out the basics of R was simple enough – it was very forgiving for a scripting language, and it helped me visualize data in myriad ways that made it possible to point out problematic areas. Using the data warehouse as input data made it so much easier, as the data was already cleaned and prepared when I fetched it (apparently this part, the data engineering, is what takes up to 80% of the time when working with data science). After a while I was confident enough to build a full script that took a dynamically sized dataset, ran a basic linear regression test between every combination of columns, then returned the significant values. This actually gave me a wealth of insight into our data such as the relationship between age and payment frequency. Unfortunately, communicating these findings to the key decision makers proved difficult, but at least we were getting somewhere!
Democratization of data
At this point in time, the data warehouse was giving us decent value for money, but it was all still gated with me as the gatekeeper – There was not much interest in the data yet, and to find anything one would still need to put together queries (which I was the only one capable of doing). Any sign of complexity seemed to turn the users off of the data.
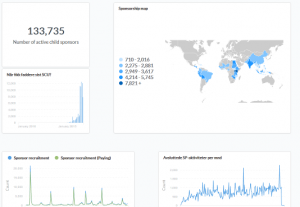
Recently I discovered a tool called Metabase through a discussion on Hacker News. An open source data visualization/exploration tool was just the thing to tickle my interest, so I set it up on an internal server to see how it worked. I used the data warehouse as a data source, and found that it was not only very feature-rich, but also user friendly enough that non-technical people might be able to use it. I once used this tool to answer a question during a meeting, and it appears those present immediately saw the value of both the tool and the data!
A Metabase dashboard
This was the pivotal step in the process – Now a whole team is on board with using the data warehouse, and have started building dashboards to watch the most important metrics. They’ve even found new useful metrics that can help understand our sponsors better! In other words, ease of use was a crucial element in attracting the users’ attention. Getting them interested and invested in the data is as important as building the entire technical stack in the first place.
Later on, if given the green light, I may share technical details and some of our findings here.
News websites have always been horrible, but lately it feels like they’re somehow getting even worse. What do I mean? Well, for one, the pages are bloated. Megabytes of javascript and images are loaded just to read a couple of paragraphs of text. The front pages are usually very loud and cluttered, and the headlines are often clickbaity rather than explanatory. Finally, the stories don’t usually give any context to the issue they discuss, but rather simply assume you’ve read their other articles earlier (especially when there are big stories in the news, the information is often spread into myriad different stories that don’t have any apparent chronology).
I wanted to get around these issues, so I started drafting a system to organize and present the information the way I wanted it.
I started out with a couple of initial premises:
I wanted to be able to read the news based on the stories and how they develop rather than reading a single isolated article. This meant I had to find a way to identify what articles/headlines are discussing the same story.
The pages must be minimalistic – no (or few) pictures, fast loading, as little javascript as possible.
Multidimensional: I want to be able to explore the news through multiple dimensions. This includes source (site), category (e.g. financial news, sports) and keywords.
Sentiment scoring: I’d come across software that could perform sentiment analysis on a text, then return a score. I had ambitions to integrate this to give a view of e.g. the sentiment development over time per keyword and/or source. Unfortunately I did not find the time to do this part during the first iteration.
I had a simple idea I started out with – Any developing story ought to be identifiable through a combination of three of the keywords (a triad) in the headline, and the context (earlier stories) would share one or two keywords. In other words, a story would probably show up in multiple papers with different titles, but with at least three similar elements. I figured the most popular combinations would most likely bubble up to the top naturally, giving me a solid list of which (combinations of) headline keywords were trending.
Here’s an outline of how I built my system:
I started out by building a web crawler. To keep it simple I stuck to using RSS feeds as the data source, then put together a side system to fetch and parse the articles themselves. I put great care into the data structure, as it would grow very fast once I started running the crawler regularly. I came up with a novel idea for the keyword triads; I made a table with three columns to store these. I would sort the keywords alphabetically, then build every possible combination of keyword in a sorted manner – that way I would avoid duplicate combinations in different order.
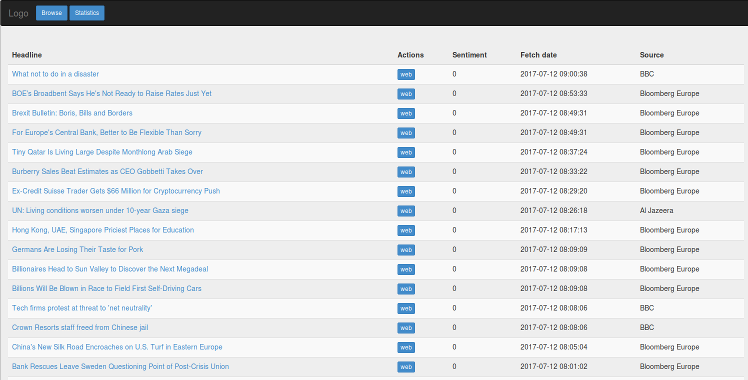
Now I needed a front-end – not as exciting to describe, I simply put together a table-like structure which would show headlines and source, with a spot for the sentiment value and a link to the article on its website.
After setting the system up and running some early tests, I realized that my initial assumption was wrong. I was unable to group the same story from different sources because the headlines differed more than expected. I got clickbait like “will make you” dominating the top of the list, which obviously do not identify one and the same story. After filtering out the news sources teeming with clickbait, I found that most “real” news are covered different enough between agencies that the headlines can be completely different. Every combination of words from one common story dominated the results at one time (when agencies actually did post the same headline), and all in all there was more garbage than value. This put an abrupt stop to this iteration of the project, and sent me back to the drawing board.
This was still a learning experience, and gave me the necessary insight to start building the second iteration.
Turns out there’s a trend where the shittiest titles tend to be the most prominent – If I’d read this article before starting, I would probably never have finished the first iteration: Study of most commonly shared headlines