I’ve previously written about the first iteration of my news crawler. The novel idea I built everything upon, that triads of keywords would bubble to the top, appeared faulty and did not bring a natural bubbling of trending stories as I first imagined it would.
Some time passed before I started building my second iteration. I had to bide my time, note down and reflect over further ideas, as well as do more research. One major discovery that would greatly affect the second iteration was the Python library Newspaper. It drastically simplifies the spidering and crawling for me, although one con is that it gives tons of duplicates (as it fetches stories from all subdomains / different newsfeeds a news agency has) – fortunately this can be dealt with in the code.
Newspaper has two more advantages I could utilize – it extracts a set of keywords from the article (which means I can use more than just the title), and does some clever NLP to summarize the article (with differing results, unfortunately some stories end up as a jumbled mess).
My first iteration did everything from scratch and used PHP, but in the second iteration I moved on to Python for the input side (although the front-end of the application is still pure PHP). I ended up with far fewer lines of code and yet more functionality – this really felt like finding the holy grail!
My new solution is a greatly enhanced version of the first one. Where I started out with simply a HN-like list of headlines and sources with keywords extracted from the headline, the system now works with an enhanced set of keywords from the entire article. I can browse by keywords (or combinations thereof), and I can see the trending keywords for the past couple of hours, days or weeks. I also have an article view (I had that before, but with only the cleaned text of the article) with an introductory blurb based on the NLP function of Newspaper.
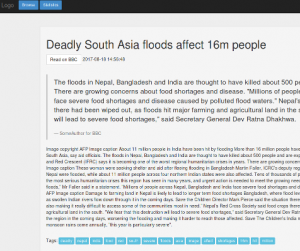
Unfortunately, after running my new version for a little while I realized it still wasn’t at the level I wanted it to be. For one, the NLP summaries of articles were unreliable and at times nonsensical. That reduces its value drastically, and I suppose using the simple blurbs given in RSS feeds could probably be a better choice. I’ll be giving that a shot in the third version.
Now for the keywords – simply extracting keywords from the article does not seem good enough for my purposes. It turns out that the “trending keywords” at any given time is dominated by various versions of “Trump”. I need to handle aliases, but also somehow identify some descriptive information about the keyword. I’m not sure if I can manage to identify the subject and object of sentences or headlines (given that the keywords are already extracted by the time I get to them, but also the fact that I wouldn’t know where to start with such a task), but something I could do is to handle it manually and build the dataset over time. For instance I could set up classifications such as verb / adjective / subject, where I lump subjects and objects together since I can’t really get the context.
My application has advanced quite a bit since its inception, but I still keep finding things to improve. As I start working on the third iteration, I’m hoping it will turn out to be ready for real use.