Today I’m going to share the story of how I helped make my organisation more data driven in their decision making.
Initial situation
I joined the company, an NGO focused on child sponsorship, in 2014. For the past couple of years they’d had trouble finding people competent in SQL and data management, and there was a huge backlog of reports and extracts waiting to be done. We had a decent amount of information available in our CMS (customer management system) – the business had been running since 1997, which means there was 20 years of data available (of variable quality, but enough to extrapolate some patterns). The historic data had been used occasionally for analyses by external companies, but we didn’t use it for anything internally. Old data was mostly left to rot.
Starting up – external analysis
When I was recruited into the job it was primarily to support the CRM team as a technical resource and system owner. There was also a demand for someone who could understand the data structures behind our systems, and could extract the required data for external consultancies who would help us do analyses and find patterns in customer behavior.
The goal of the initial project was to identify customers who are likely to quit, or churn (as is the CRM term). The team had already decided on a bunch of metrics they thought could affect this, such as e.g. the number of unpaid invoices and how long it had been since we got in touch with them. Identifying and extracting all this information was my task, and it was an ideal way to get to know the data structures I had to deal with (our application’s database was not exactly ACID compliant, and had a steep learning curve).
I built a staging database to contain all the calculated values, and stored it all in one huge, flat table that was populated one column at the time. When it was time for our consultants to do their data crunching, we could simply send them an extract of the complete table. Any tweaks or new fields that came up as requirements along the way could be done quickly and implemented with a quick rebuild.
We finally got our results and ended this project, leaving the staging database dead for now. We got the rules we needed to predict who was 50% more likely to churn and added the relevant measures in our customer handling procedures. This was certainly a step in the right direction.
Building on what I learned
After completing the analysis project we started exploring the idea of a permanent staging database, or a data warehouse. This could surely make a ton of information much more accessible to the organisation, and could take us in a more data-driven direction. In addition, we could move our CRM tool to use the staging database as a data source rather than the live system, simplifying the logic we needed in the tool and most importantly reducing the load on a live system (we had cases where employees were unable to update data in the system because of blockage from heavy queries in the CRM tool).
The development of this system was done in a very small team – a colleague and myself, with the occasional insight from a consultant. We built on the previously developed definitions and queries, and expanded thoroughly with every useful dimension we could come up with. The problem with such a large dataset is that it takes a rather long time to build, which means that the data will never be fully up to date. To mitigate this issue somewhat, we put together a daemon that watched the source database for updates and then pushed these to an update queue in the warehouse. While not real-time, this would ensure that data would at least update throughout the day. We also set up a full rebuild at midnight, which would purge the queue and start fresh. This would ensure that if the queue got backed up, it would only be a problem that one day.
The system would also have to support multiple data sources – while the system did have a concrete set of base tables, it would also have a structure for additional data. For instance, we would fetch usage data from our web portal as well as supporting a geolocation-based customer segmentation system we were planning to try out.
Once we had the data warehouse established and running, I started looking into what we could do to utilize the data. Thinking back to our churn analysis where the consultancy had automated their analysis with an ancient excel worksheet (which took days to execute), I was certain that modern technology could outperform them while simplifying the process drastically. I’d seen R discussed time and time again on Hacker News and StackOverflow, so I figured that would be a logical place to start.
Figuring out the basics of R was simple enough – it was very forgiving for a scripting language, and it helped me visualize data in myriad ways that made it possible to point out problematic areas. Using the data warehouse as input data made it so much easier, as the data was already cleaned and prepared when I fetched it (apparently this part, the data engineering, is what takes up to 80% of the time when working with data science). After a while I was confident enough to build a full script that took a dynamically sized dataset, ran a basic linear regression test between every combination of columns, then returned the significant values. This actually gave me a wealth of insight into our data such as the relationship between age and payment frequency. Unfortunately, communicating these findings to the key decision makers proved difficult, but at least we were getting somewhere!
Democratization of data
At this point in time, the data warehouse was giving us decent value for money, but it was all still gated with me as the gatekeeper – There was not much interest in the data yet, and to find anything one would still need to put together queries (which I was the only one capable of doing). Any sign of complexity seemed to turn the users off of the data.
Recently I discovered a tool called Metabase through a discussion on Hacker News. An open source data visualization/exploration tool was just the thing to tickle my interest, so I set it up on an internal server to see how it worked. I used the data warehouse as a data source, and found that it was not only very feature-rich, but also user friendly enough that non-technical people might be able to use it. I once used this tool to answer a question during a meeting, and it appears those present immediately saw the value of both the tool and the data!
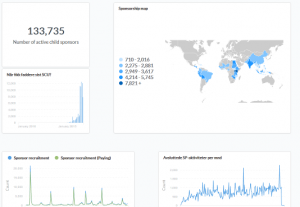
This was the pivotal step in the process – Now a whole team is on board with using the data warehouse, and have started building dashboards to watch the most important metrics. They’ve even found new useful metrics that can help understand our sponsors better! In other words, ease of use was a crucial element in attracting the users’ attention. Getting them interested and invested in the data is as important as building the entire technical stack in the first place.
Later on, if given the green light, I may share technical details and some of our findings here.